Blocking Trypophobia-Triggering Images with Deep Learning — From Model Training To Deploying in Chrome
TL;DR: I curated a dataset of trypophobia-triggering images, trained models with TensorFlow, exported to Tensorflow.Js, and shipped it as a Chrome extension.
All trypophobia-triggering images are blocked in this Google Image search
What is Trypophobia?
Trypophobia is a specific phobia of a cluster of small holes. The most well-known trigger is lotus seedheads. In a relatively small study done in 2013, 16% of the 286 participants experience discomfort when shown trypophobia-triggering photos.
Trypohobia is not a well-studied phenomenon so there is very little understanding of the cause and treatment. To make things worse, people on the Internet sometimes intentionally photoshop lotus seedhead or other trypophobia-triggering patterns to normal images. If you have trypophobia, it might be a nightmare to just browse the net because you never know when the dreaded lotus seedhead is going to show up. This chrome extension prevent users with trypophobia from exposing to these trypophobia-triggering images.
Rest assured that I am not going to show any trpophobia-triggering images in this blog post.
What does Trypophobia Blocker do?
Trypophobia Blocker contains a convolutional neural network that can classify whether an image is trypophobia-triggering or not. This neural network is run against all images displayed on a page and blurs out any images that are trypophobia triggering. No data is sent to me as all computation occurs locally.
Users have the option to provide feedback for the network — you can unblur and image if you think it is a regular image, or you can blur out the image manually if it is triggering trypophobia. The image URL is sent to a server to improve the dataset and the model further. Users’ IPs or browsing history is not recorded.
The network is validated against a hold-out test set and has a precision of 97.12% and a recall of 85.63%. More on this test set in the next section.
Why this Project?
This idea comes from my girlfriend who suffers from a pretty severe case of trypophobia. When she browse Instagram or Facebook, she always find unexpected images on triggering her trypophobia. I thought this is a perfect use case how deep learning can be used to improve someone’s quality of life.
Show Me the Dataset
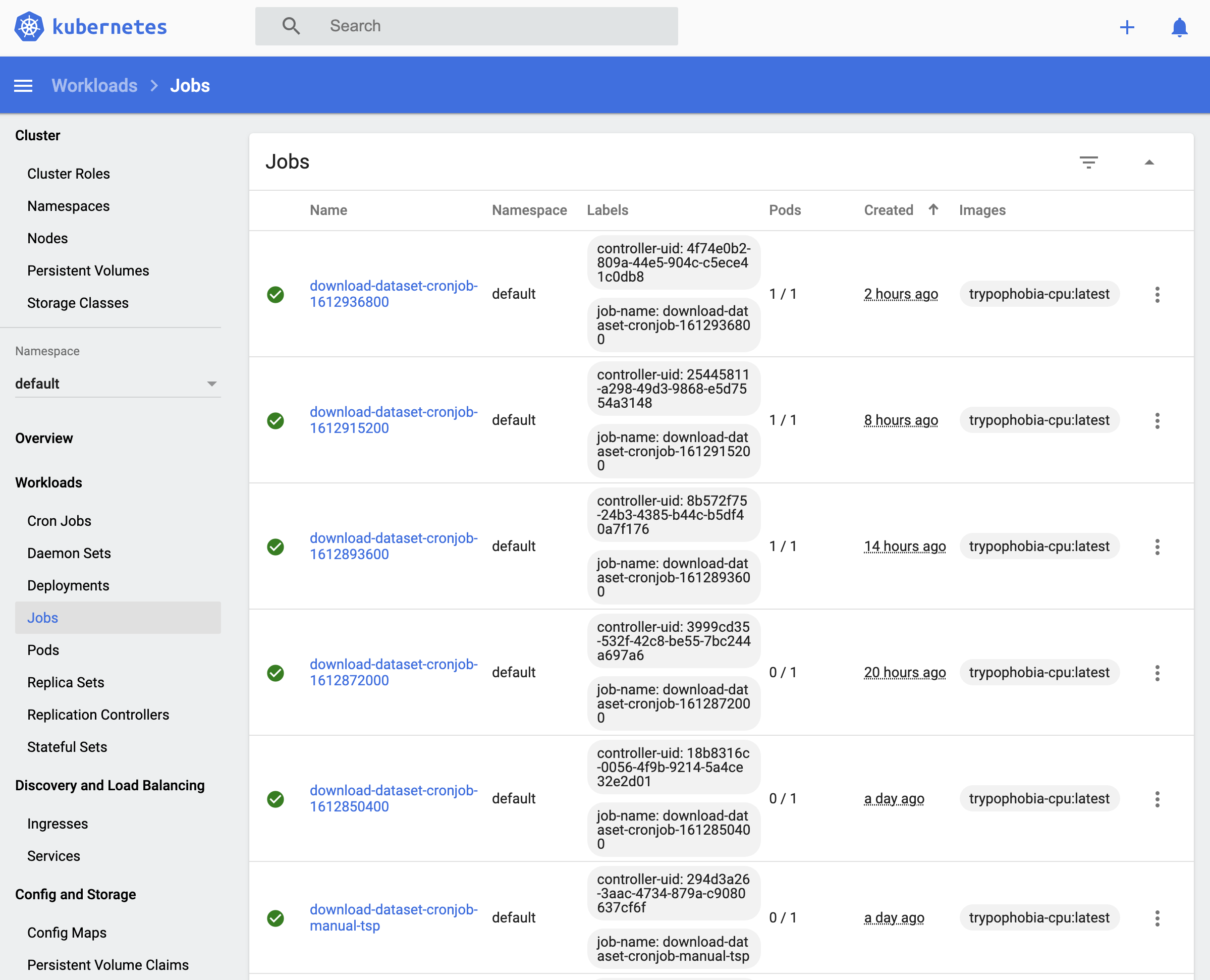 Cron jobs are scheduled on a kubernetes cluster to download the latest images
from various subreddits.
Cron jobs are scheduled on a kubernetes cluster to download the latest images
from various subreddits.
Perhaps surprising to the general public about AI, the most important component of this project is actually the dataset, especially for a well-established problem like this — image classification. A good amount of effort is spent on scraping the Internet for trypophobia-triggering images.
The base of this dataset comes from Artur Puzio’s dataset on Kaggle This contains 6k trypophobia-triggering images by scraping Google Image and the r/trypophobia subreddit, and 10.5k normal images.
I further expanded this dataset by scraping r/trypophobia subreddit every 6 hours and gather normal images by scraping images from 15 other subreddits (e.g. r/pics, r/OldSchoolCool, r/memes, r/aww, etc.)
One challenge of gathering this dataset is that the Reddit API does not return all posts, but only the top or most recent 1000 posts. So to capture all images submitted to the r/trypophobia subreddit, the crawler is schdeuled to run every 6 hours.
To better measure real-world performance, special care is taken to curate the test dataset. Below shows the construction of the test set.
- “Normal”
- Top-100 most upvoted images all-time
- Top-50 most upvoted images today
- Top-50 most upvoted image this week
- Top-50 most upvoted images this month
- “Trypophobia-triggering”
- Top-25 most upvoted images in r/trypophobia all-time
- Top-25 most upvoted images in r/trypophobia this week
The test set is constructed in the way that it emphasizes popular images because they are the images that the user might stumble into after all.
As of February 2021, this dataset now has almost 300k images with 14k being trypophobia-triggering.
Model Training
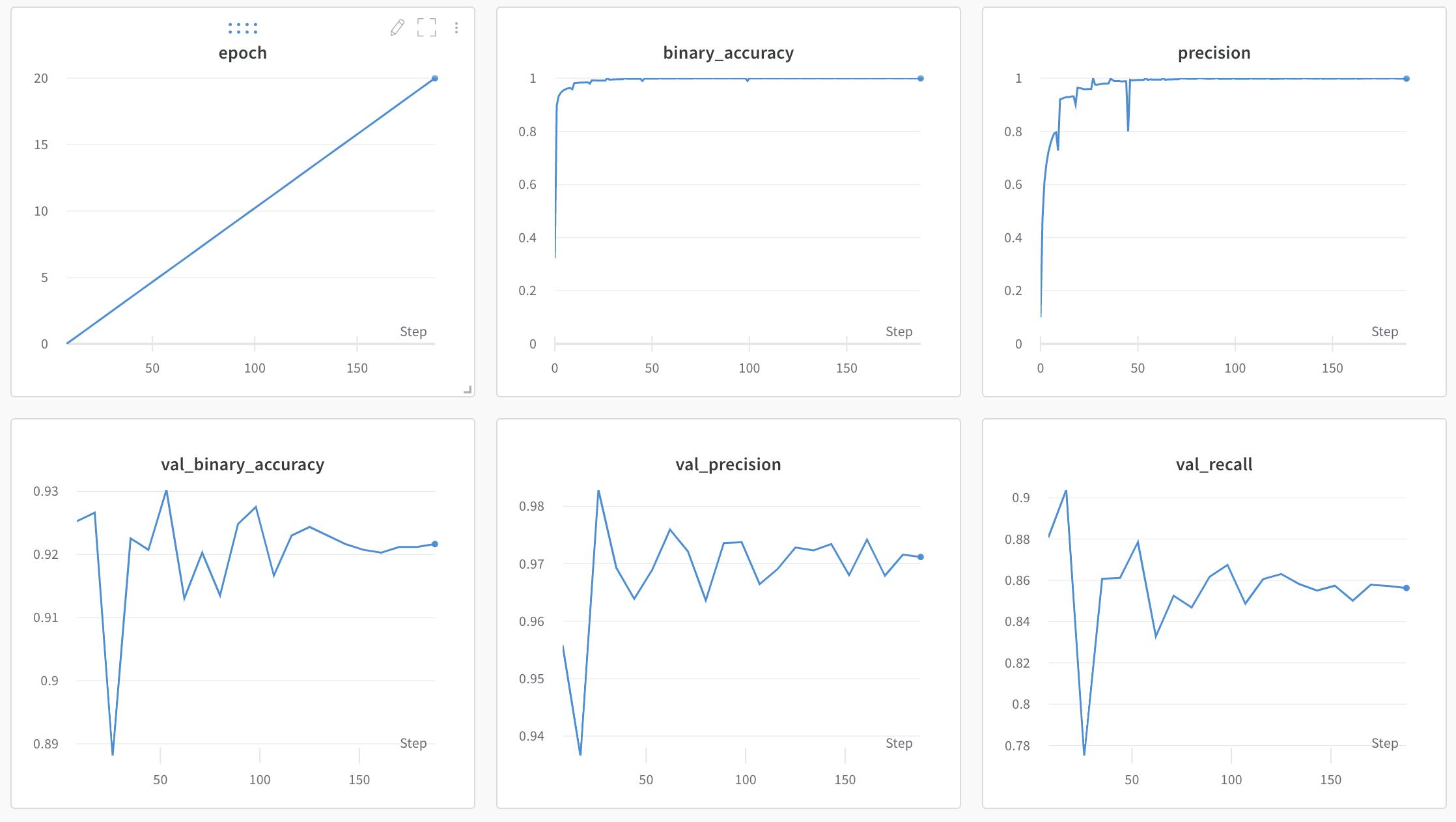 Model training metrics on Weights and Biases
Model training metrics on Weights and Biases
The underlying model is a fine-tuned MobileNet v1 with 2.23M parameters. I tried to use a more modern network like EfficientNet-b0 but Tensorflow.js does not seem to be able to convert the weights and the graph correctly.
Another unexplored alternative is to use a shallower network. A shallower network (fewer layers and FLOPs) makes sense in this use-case because the trypophobia-triggering pattern is local and context is usually not necessary to classify whether the image is trypophobia-triggering.
Fixing the Labels
A sharp reader must have noticed that we are treating images outside the r/trypophobia as normal. But this is untrue — a top-voted image can be trypophobia-triggering.
So every time a model is trained, labeling jobs are created to correct the image with suspicious labels. Specifically, we select ambiguous images (with predicted probability close to 0.5), strong false positive (i.e. images with the normal label but predicted to be trypophobia-triggering with high confidence) and strong false negative (i.e. images labeled as trypophobia-triggering but predicted to be normal with high confidence.)
Roughly 500 images will be relabeled each round and about 40% of the labels will be corrected by human moderators.
Deploying as Chrome Extension
Now that we have a trained model, we would like to run our trained model on every image that the browser is showing the user. However, this is easier than done.
The Chrome extension has two components: content.js that get injected into the
webpage and a background.js that runs in the background.
I set up 2 types of event listeners on content.js — DOMContentLoaded and
MutationObserver. When an image gets added to the DOM, it will be blurred out
since we don’t know whether it’s trypophobia triggering or not. Then a “message”
containing the image URL will be sent to the background.js. background.js
contains the network and listen to all the messages from content.js.
Once content.js hears back from model inference results from background.js,
it will either apply a stronger blur if the image is trypophobia triggering or
remove the blur entirely for normal images.
User Feedback
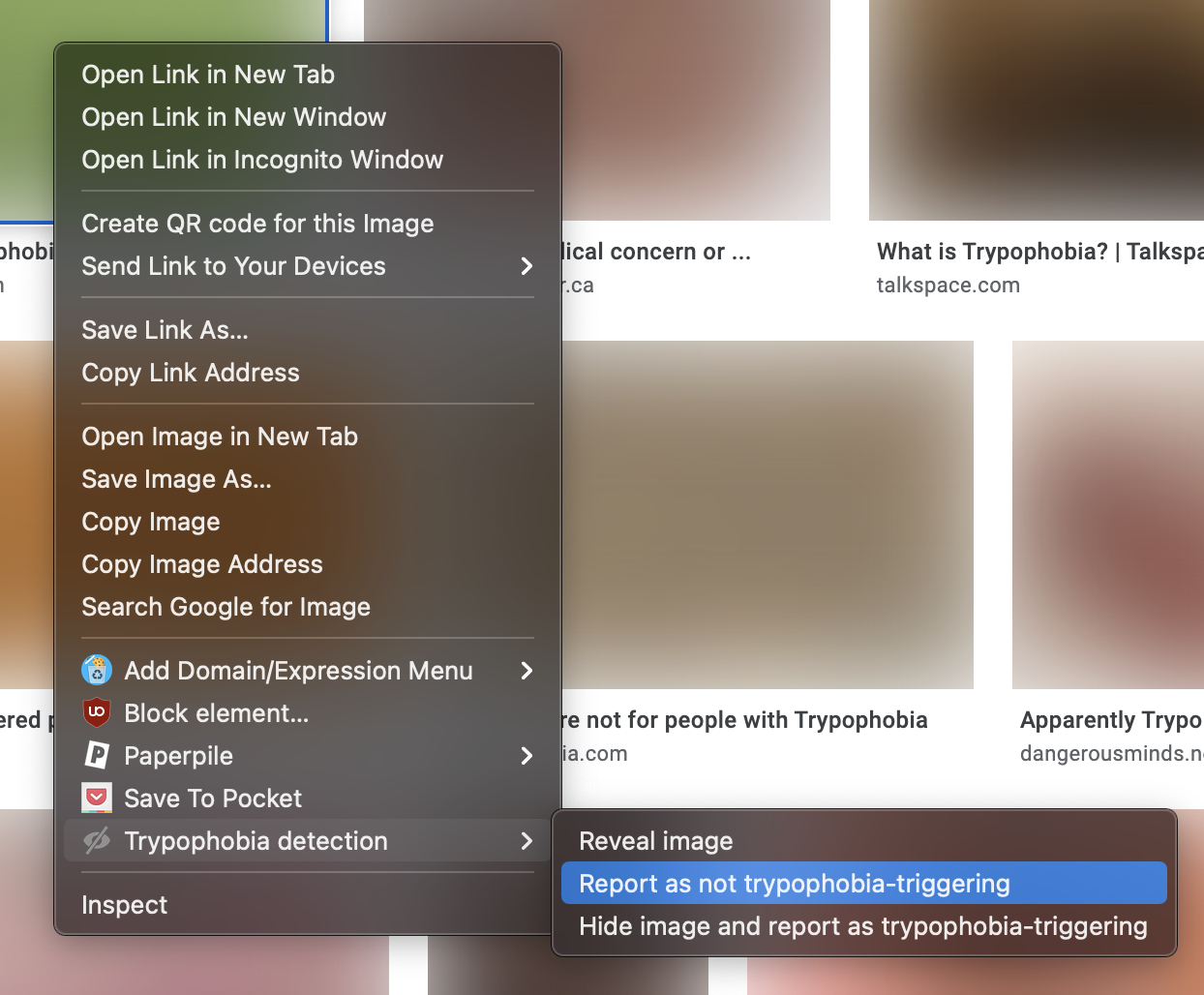
If the model makes a mistake in the wild, there is a mechanism to allow the user to provide feedback to the model. The user can either report an image as trypophobia-triggering and blurs out the image, or reveal a blurred image and report the image as normal. This feedback is logged in a simple flask app hosted on Heroku.
This Heroku app uses a Postgres database to store the user feedback. Only the image URL and time of submission are collected and browsing history is not recorded in any way.
Closing Thoughts
Shipping a production machine learning model end-to-end is rarely talked about. Most focus on the glory parts of machine learning, such as new fancy architecture, an outrageous amount of parameters, or the global-warming-inducing amount of GPUs required to train the model.
This project shows you that data collection, user-feedback for continuous improvement are just as important as the model itself. We are in an era where every software engineer can easily develop a machine learning model. Machine learning practitioners should put more focus on what happens before model training and after model training.